
How to Train a ML Model to Defeat APT Cyber Attacks
Round 2: Fuchikoma VS CyAPTEmu: The Weigh In
Round 3: Fucikoma v0: Learning the Sweet Science
Round 4: Finding the Fancy Footwork (Releases 2020.02.19)
Round 5: Fuchikoma v2: Jab, Cross, Hook, Perfecting the 1-2-3 Punch Combo (Coming Soon)
In preparation for the second round of MITRE ATT&CK evaluations, CyCraft Senior Researcher C.K. Chen and team went about designing an emulation of an APT attack, which they named CyCraft APT Emulator or CyAPTEmu for short. CyAPTEmu’s goal was to generate a series of attacks on Windows machines. Then, a proof of concept threat hunting machine learning (ML) model was designed to specifically detect and respond to APT attacks. Its name is Fuchikoma.
Last round, Fuchikoma v0 got knocked out by CyAPTEmu. Major Kusanagi of Section 9 (the purple-haired lady pictured above) was not pleased.
The thought experiment Fuchikoma v0 model gave insight into the four main challenges when designing a threat hunting ML model: having a weak signal, imbalanced data sets, a lack of high quality data labels, and the lack of an attack storyline.
In keeping with our boxing analogy, Fuchikoma v0 lost because it couldn’t decipher similar movements (such as footwork) as benign or malicious, was too busy focusing on everything in and out of the ring to properly identify malicious attacks, had trouble identifying similar attacks, and couldn’t string the attacks together to aid in fight analysis. With all this in mind, it’s no wonder Fuchikoma v0 got knocked out.
Introducing Fuchikoma v1.
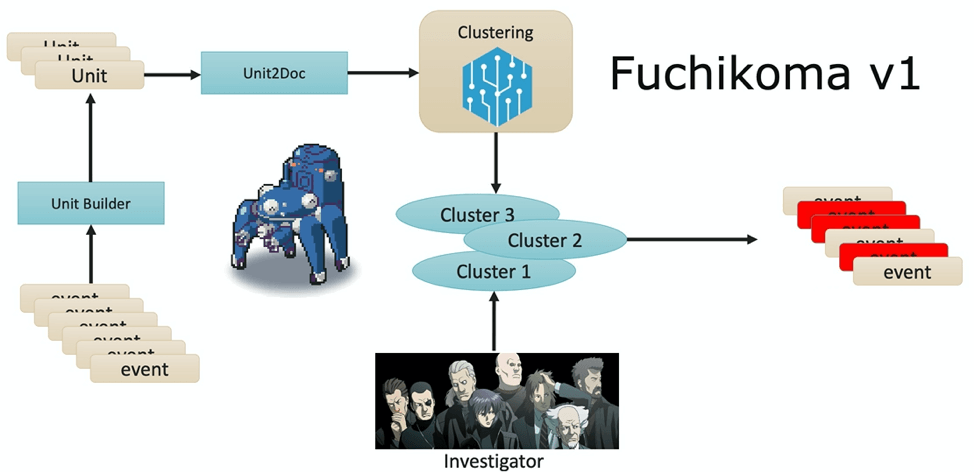
Each AU (pictured below) would be a mini process tree with a total depth of 5 layers; each process creation event (the cmd 1 node in the graphic below) was linked with its parent and up to three tiers of child processes. TF-IDF was used for vectorization of the command lines of the processes in Unit2Doc, which were then sent further down the ML pipeline for clustering.

Pure supervised learning would be inefficient here for the real world as investigators (Fuchikoma’s friends at Section 9) would have to individually label each of the numerous and diverse events as malicious or benign. Instead, unsupervised learning algorithms, such as k-means, could cluster many similar events prior to labelling thus reducing the number of labels that needed to be generated by our investigators.
Since k-means gives more weight to the larger clusters, our investigators (Fuchikoma’s friends from Section 9) might know with a higher degree of confidence that the larger clusters would not contain malicious events as 98.9 percent of events are benign. We can see from this that maybe highlighting outliers might be more ideal.

After clustering, our investigators (Fuchikoma’s friends from Section 9) wouldn’t need to label each of the billion diverse events individually but rather label each of the clusters — a dramatic decrease in time and resources.
The results were …

… not great.
Labelling ten clusters (k was valued at 10 in a few of our tests) is better than labelling one billion; I’m sure we can all agree on that. Clustering is a step in the right direction; however, k-means presented two new challenges.
Setting the value of k (the number of clusters to be formed) before the initial labelling isn’t ideal, as it is hard to determine the clusters a priori. For example, while in a few of our tests k was valued at 10, this value would prove difficult to determine for each environment Fuchikoma needs to inspect. I mean, do you know the ideal number of centroids to accurately cluster all of the daily process creation events for your office environment?
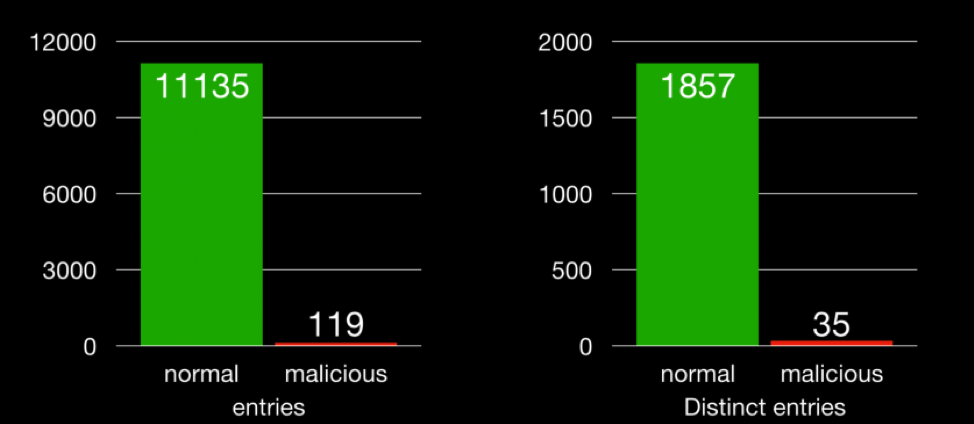
Our second issue is the imbalanced data set. There were 11,254 events generated; we’re looking for the 119 (1.1 percent) that are malicious. This second problem is compounded by the first problem. Perhaps, there should be eight clusters — each with hundreds of thousands of data points, and we’re looking for two points in that cluster. Not ideal. Don’t forget that some malicious activity could appear identical to benign activity (e.g., “netstat” or “whoami”). Despite these issues, clustering could still prove useful, as the initial conceit of labeling groups as opposed to individual dots can still be a time saver; however, highlighting outliers may prove better. Fuchikoma v2 will need more upgrades to its pipeline.
C.K. Chen and team decided Fuchikoma v2 should leverage outlier detection as it is effective at cutting the noise out of data sets by labelling them as outliers. However, instead of ignoring these outliers, Fuchikoma’s friends at Section 9 would focus on these outliers as these data sets theoretically have a higher probability of being malicious.
Fuchikoma will have to get more training in order to properly defeat CyAPTEmu. Let’s hear from our investigator team from Section 9 on Fuchikoma v1’s performance.




